
编译:雾月&白丁,极客 web3
本文为 Nervos 联创 Jan 在 2019 年HBS Blockchain+Crypto Club Conference 上的讲话,主题围绕着 Layer2 与 Layer1 之间的关系展开,明确提出模块化区块链会是正确的方向,还谈及了区块链数据存储机制的问题。同时Jan 也抛出了一个颇为有趣的话题:Layer2 的兴起若导致 Layer1 饥饿,该怎么解决。
作为最早一批支持 Layer2 与模块化区块链叙事的团队,Nervos 的主张在 18、19 年时颇具前瞻性,彼时的以太坊社区还对分片抱有不切实际的幻想,而高性能单片链的叙事也处于甚嚣尘上的状态,尚未被充分证伪。
但在 2024 年的今天,回看以太坊 Layer2 在实践当中暴露出的问题,以及 Solana 为代表的「高性能公链」在去中心化与免信任问题上的弊端,不得不说 Jan 在 5 年前的观点很有先见之明。出于对 Layer2 本身的兴趣,「极客 web3」将 Jan 的讲座以文字版的形式整理成文,发表于此,欢迎 Nervos 与以太坊、比特币社区的 Layer2 爱好者们共同学习与讨论。

以下为 Jan 的讲座原文。
Layer1 和 Layer2 的定义
这是我对 L1 和 L2(二层网络)的定义,如图。

首先要强调,Nerovs 只是一个努力满足去中心化经济需求的区块链网络,并不负责解决「所有问题」。在我们的认知里,Layer1 和 Layer2 的区别,关键在于共识的强弱。L1 网络必须具有最广泛的共识,即「全球共识」。通过无需许可的全球共识,世界上任何人都可以参与到 L1 的共识过程中,最终 Layer1 可以作为去中心化经济的「锚」。从这个角度来讲,我们可以把 L1 称为「共识层」。
相比之下,L2 网络的共识范围会小一些,其参与者可能仅来自某个国家,或某个行业,甚至是某家公司或机构,亦或是范围很小的社区。L2 在共识范围上的牺牲是一种代价,换来了其他方面的进步,比如更高的 TPS、更低的延迟和更好的可扩展性等。我们可以把 L2 称为「协议层」,而 L1 和 L2 之间往往通过跨链桥进行连通。
必须要强调,我们构建 L2 网络,目的并不仅仅是解决区块链的可扩展性问题,而是因为分层架构是让「模块化区块链」最容易落地的途径。所谓模块化区块链,就是将不同类型的问题投放到不同的模块中去解决。
很多人一直在讨论区块链的合规和监管问题,那么我们该如何将比特币或以太坊纳入现有的监管框架中?分层架构也许是解决该问题的一个答案。直接在 Layer1 层面添加迎合监管要求的业务逻辑,可能会破坏其去中心化和中立性,因此与合规相关的逻辑可以单独在 Layer2 上实现。
Layer2 可以根据特定的法规或标准来定制,比如建立一个基于许可制的小型区块链,或是状态通道网络等东西。这样即实现了合规性,又不会影响到 Layer1 的去中心化和中立性。
另外,我们还可以通过分层架构解决安全性和用户体验之间的冲突。类比来说,如果你想保证自己的私钥安全,就要牺牲一定的便捷性,而区块链也是如此,如果你想保证区块链的绝对安全,就要牺牲一些东西,比如该链的性能等等。
但如果使用分层架构,我们就可以在 L1 网络上完全追求安全性,而在 L2 网络上牺牲少许安全性以换取更好的用户体验。比如我们可以在 L2 上使用状态通道来优化网络性能,降低延迟。所以说,Layer2 的设计无非是安全性和用户体验之间的权衡。
上述内容自然而然地就引出了一个问题:是不是任何一条区块链都可以作为 Layer1?

答案是否定的,首先我们必须明确,Layer1 网络的去中心化和安全性高于一切,因为我们必须通过去中心化来实现抗审查。追求 Layer1 的安全,究其根本,是因为 L1 是整个区块链网络的根,是整个加密经济系统的锚。
在这样的评判标准下,比特币和以太坊无疑是最经典的 L1 网络,它们拥有极强的共识范围。除这二者之外,大多区块链都不满足 L1 的标准,共识程度较低。比如说,EOS 的共识就不达标,只能充当一个 L2 网络,更何况它的一些规则只适用于其自身。
当前 Layer1 网络存在的问题
明确 Layer1 的定义后,我们要指出,现有的一些 L1 网络存在三个问题,这些问题即使在比特币和以太坊中,也一定程度上存在:

1.数据存储的公地悲剧问题
我们使用区块链时需要支付一定的费用,但在比特币的经济模型中,手续费结构设计中只考虑了计算成本和网络带宽成本,没有成熟地考虑数据存储成本。
比如用户向链上存储数据只需要支付一次费用,但存储期限却是永久的,所以人们可以滥用存储资源,将任何东西都永久上链,最终网络里的全节点要承担越来越高的存储成本。这带来了一个问题:任何节点运行者想参与进该网络中的成本,都会被最大限度地提升。

假设某区块链的状态 / 账户数据总计超过 1TB,则不是每个人都能轻松同步完整的状态和交易历史。在这种情况下,就算你能同步到完整的状态,也很难再去自行验证对应的交易历史,这会削弱区块链的免信任性,而免信任恰恰是区块链最核心的价值观。
以太坊基金会意识到了上述问题,据此在 EIP-103 中加入了有关存储租赁制的设计,但是我们认为这不是最优的解决方案。

我们在 Nervos 中提出了全新的状态模型,称为「Cell」,可以看作是 UTXO 的一种扩展。在比特币 UTXO 的状态中,你能储存的只有比特币的余额数值,而 Cell 中可存储任意类型的数据,并将比特币 UTXO 的 amount 和 integer value 泛化为「Capacity」,用以指定 Cell 的最大存储容量。
通过这种方式,我们将 CKB 上原生资产的数量和状态大小绑定在一起。任何一个 Cell 占据的空间不能超过其容量限制,所以数据总量会保持在一定范围内。
而且我们通过较为合适的代币通胀率来确保状态数据的大小不会对节点运行者造成干扰。任何人都可以参与到 CKB 网络中,他们可以验证历史数据,也可以验证最终的状态是否有效,这就是 CKB 针对区块链中存储问题提出的解决方案。
2.Layer1 饥饿问题
如果我们在 Layer2 上进行扩展,并将大量交易活动放到 Layer2 上进行,势必会导致 Layer1 上的交易数量下降,Layer1 矿工 / 节点运行者的经济奖励也会相应降低。这样的话,Layer1 矿工 / 节点运行者的积极性会下降,最终导致 Layer1 的安全性下降。这就是所谓的 Layer1 饥饿问题。
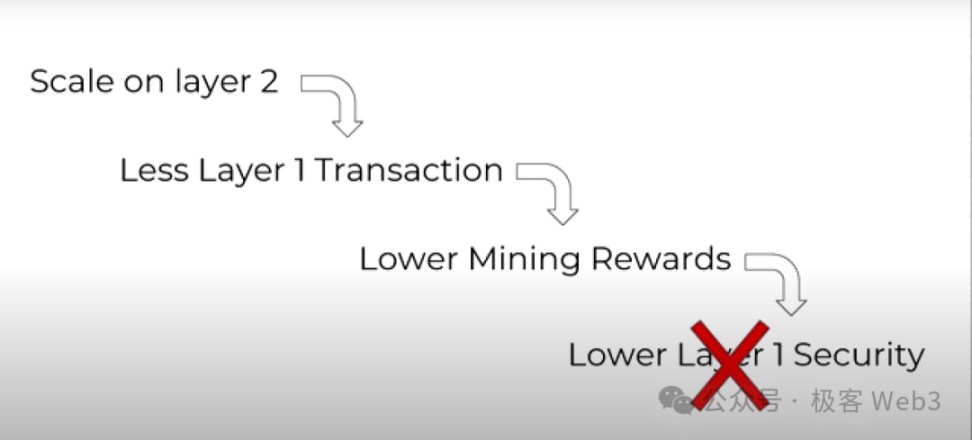
举个极端的例子,如果我们将所有的交易活动都转到 L2,那么作为其根基的 L1 将不可持续。所以如何才能解决这个问题呢?

对此,我们要区分区块链网络中有哪些种类的用户,简单来说可分为 Store of Value Users(SoV user,价值存储用户)和 Utility Users(应用型用户)。
仍以 CKB 为例,SoV Users 将原生资产 CKB 代币作为价值存储的手段,而 Utility Users 则利用 Cell 来存储状态。SoV Users 对于 CKB 代币通胀导致的价格稀释是排斥的,而 Utility User 必须向矿工支付状态存储费用,该费用与数据存储的持续时间和占用空间成正比。
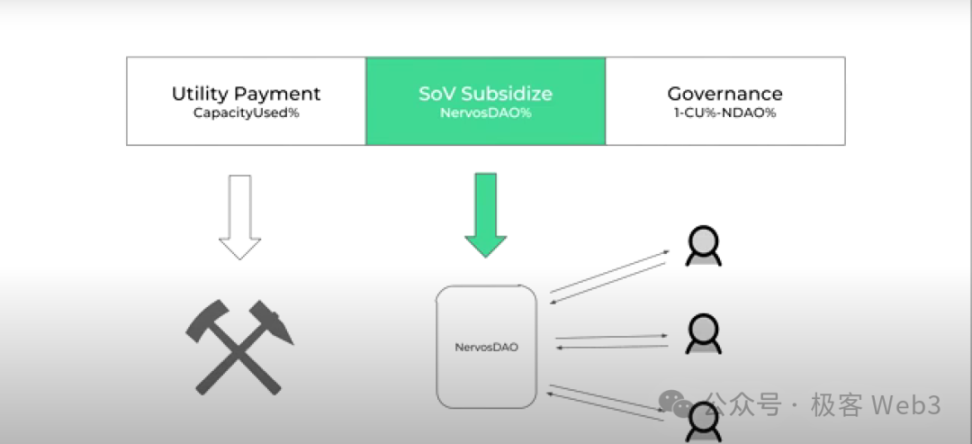
我们会在网络中持续发行新的 CKB 代币以制造固定的通胀率,并将其付给矿工,这就相当于稀释了 Utility Users 手中的代币价值(这就是 CKB 经济模型中三种发行模式之一的「二级发行」,该方式每年固定发行 13.44 亿枚 CKB 代币,具体内容可以查看《解读 Stable++:RGB++ Layer 首个稳定币协议正式启航》)。
该过程中 SoV 用户的资产同样被稀释,因此我们可以给他们一定的补贴抵消通胀损失(这就是后来的 NervosDAO 分成)。也就是说,矿工从 CKB 通胀中获得的收益,实际上只由 Utility User 来支付。很快我们将发行 CKB 的代币经济论文,相关问题在其中会详细说明。
基于这样的代币经济学设计,即使 CKB 链上没有任何交易活动,矿工也能获得报酬,进而我们可以与任何「价值存储层」或 Layer2 兼容。综上所述,我们通过有意为之的固定通胀,解决 Layer1 饥饿问题。
3.加密原语的缺乏
用户需要不同的加密原语,以使用不同的加密方式或不同的签名算法,比如 Schnorr、BLS 等。

想要成为一条 Layer1 区块链,必须考虑如何与 Layer2 进行互操作。以太坊社区中有些人提议使用 ZK 或 Plasma 的方式实现 Layer2,但是如果没有 ZK 相关的原语,你如何在 Layer1 上完成验证呢?
另外,Layer1 也要考虑与其他 Layer1 之间的互操作性。仍用以太坊举例,有人要求以太坊团队将 Blake2b 哈希函数预编译为 EVM 兼容的操作码。该提案的目的是将 Zcash 和以太坊进行桥接,以便用户在二者之间交易。上述提案虽然两年前就已经提出,但直到现在还没有实现,究其原因即缺乏对应的加密原语,这对 Layer1 的发展造成了严重阻碍。
为解决该问题,CKB 构建了一个抽象程度很高的虚拟机,即 CKB-VM,与比特币虚拟机和 EVM 截然不同。举个例子,比特币有一个专门的 OP_CHECKSIG 操作码,用于验证比特币交易中的 secp256k1 签名。而在 CKB-VM 中,secp256k1 签名并不需要特殊处理,只需用户自定义的脚本或智能合约即可进行验证。
CKB 也使用 secp256k1 作为其默认的签名算法,只不过是运行在 CKB-VM 中,而不是作为硬编码的加密原语。
CKB 构建虚拟机的初衷是,在 EVM 等其他虚拟机中运行加密原语非常慢,所以要改善这种情况。单个 secp256k1 签名在 EVM 中的验证耗时大概是 9 毫秒,而使用相同的算法在 CKB-VM 计算,耗时仅为 1 毫秒,这是将近十倍的效率提升。

所以 CKB-VM 的价值在于,现在用户可以在其中自定义加密原语,且绝大多数可以被 CKB-VM 兼容,因为 CKB-VM 采用了 RISC-V 指令集,任何由 GCC(GNU Compiler Collectio,一种广泛使用的编译器集合)编译的语言都可以在 CKB 上运行。
另外,CKB-VM 的高度兼容性也提升了 CKB 的安全。正如开发者总说的「Don't implement your own version of crypto algorithms, you will always do it wrong」,自行定义加密算法往往会带来不可预见的安全风险。
总结一下,CKB 网络使用各种方法,解决了我所提出的 L1 网络面临的三种问题,这就是 CKB 为什么可以称为一个合格的 Layer1 网络的原因。













